
코딩응급실
[Python] 네이버 리뷰(닉네임, 사진url, 내용 등) 크롤링하기 with. selenium 본문
1) 사전준비
먼저 크롬웹드라이버를 깔아야 한다고 한다.
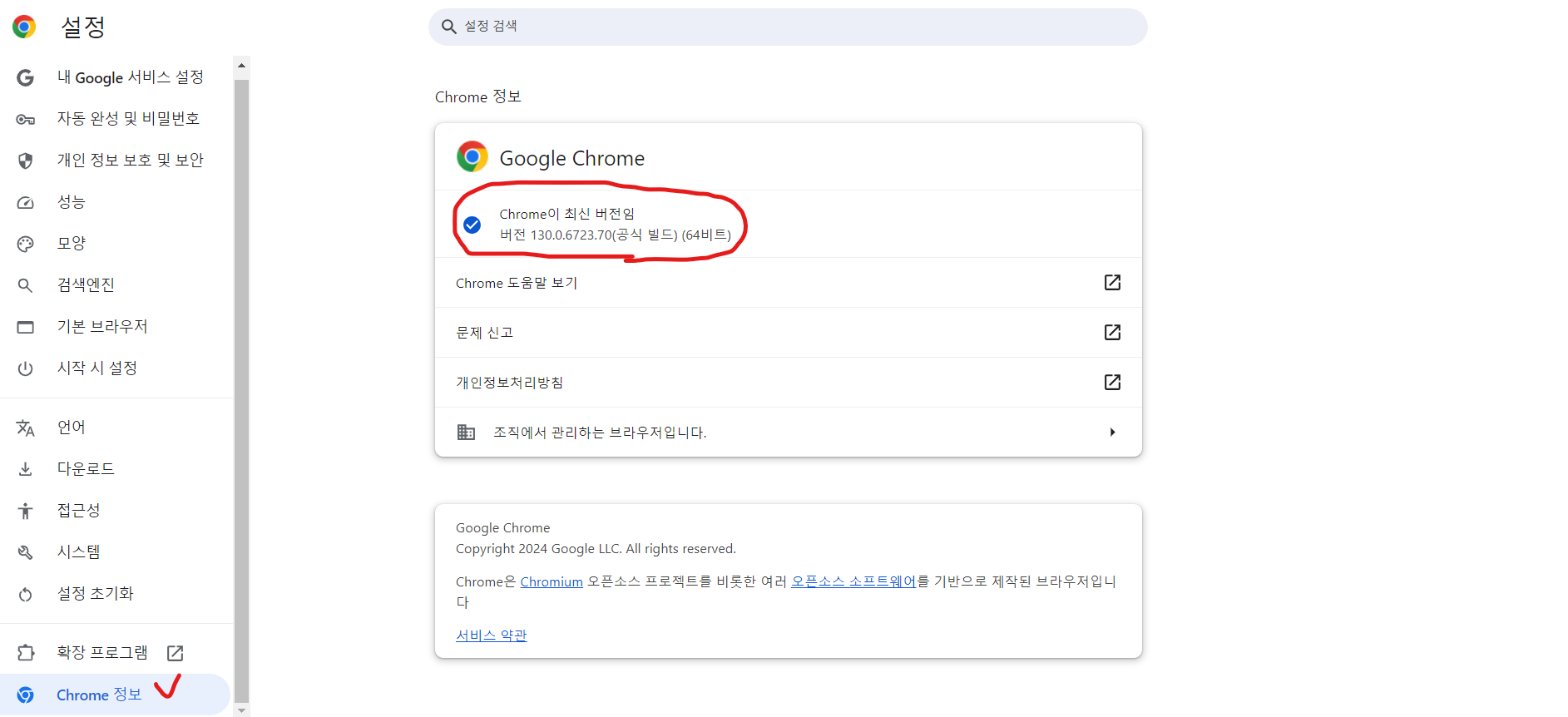
내 크롬 버전에 맞게 다운로드를 해야 한다.
115 이상인 경우:
https://googlechromelabs.github.io/chrome-for-testing/
Chrome for Testing availability
chrome-headless-shellmac-arm64https://storage.googleapis.com/chrome-for-testing-public/130.0.6723.69/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
내 버전은 130.0.6723.70 (64비트)이다.
그러므로 아래에서 Stable을 눌러서 내 컴퓨터 사양에 맞는 걸로 골라서 다운로드를 진행하면 된다.
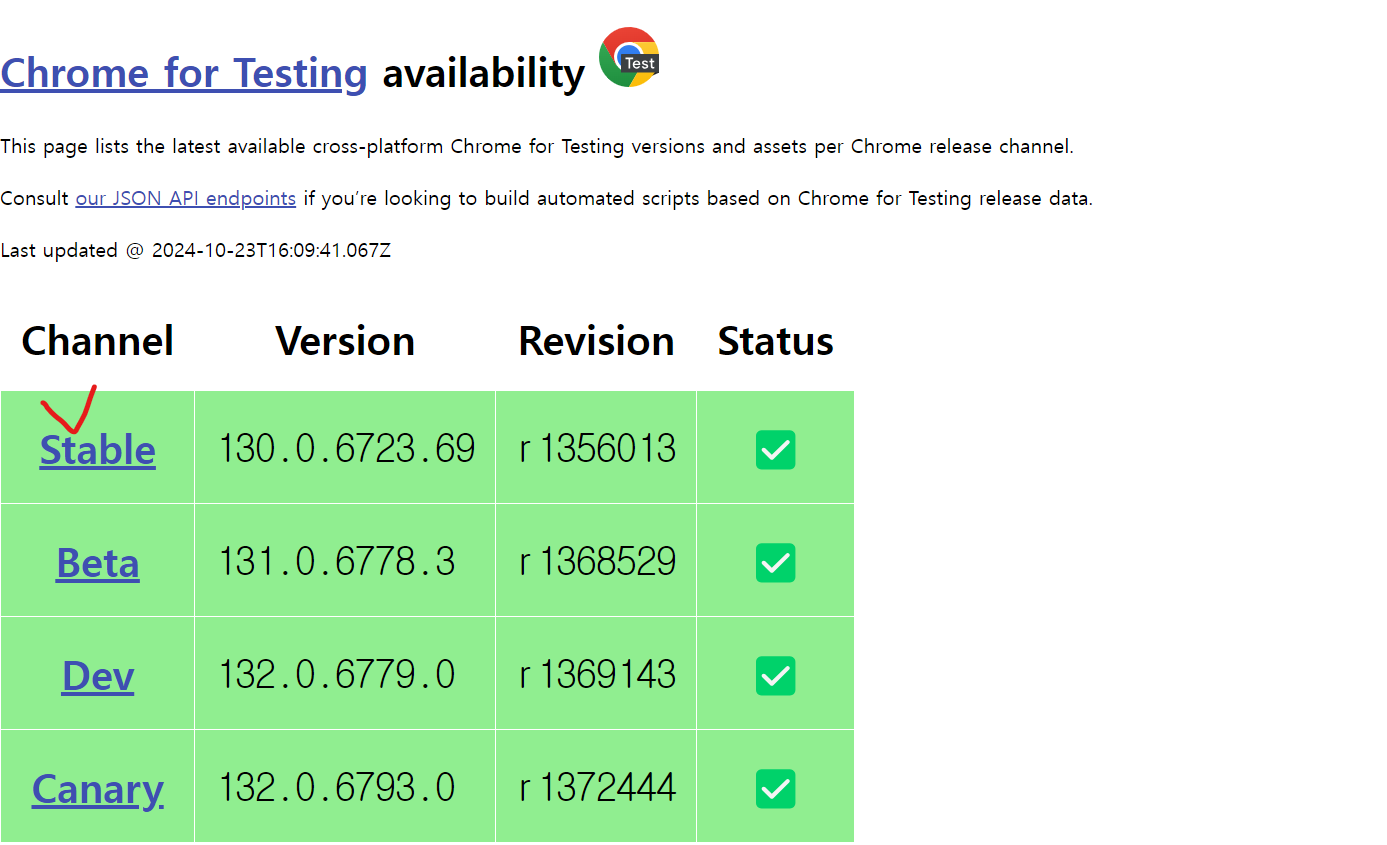
그리고 아래처럼 해당 주소를 복사해서 주소창에 넣으면 자동으로 다운로드가 된다.
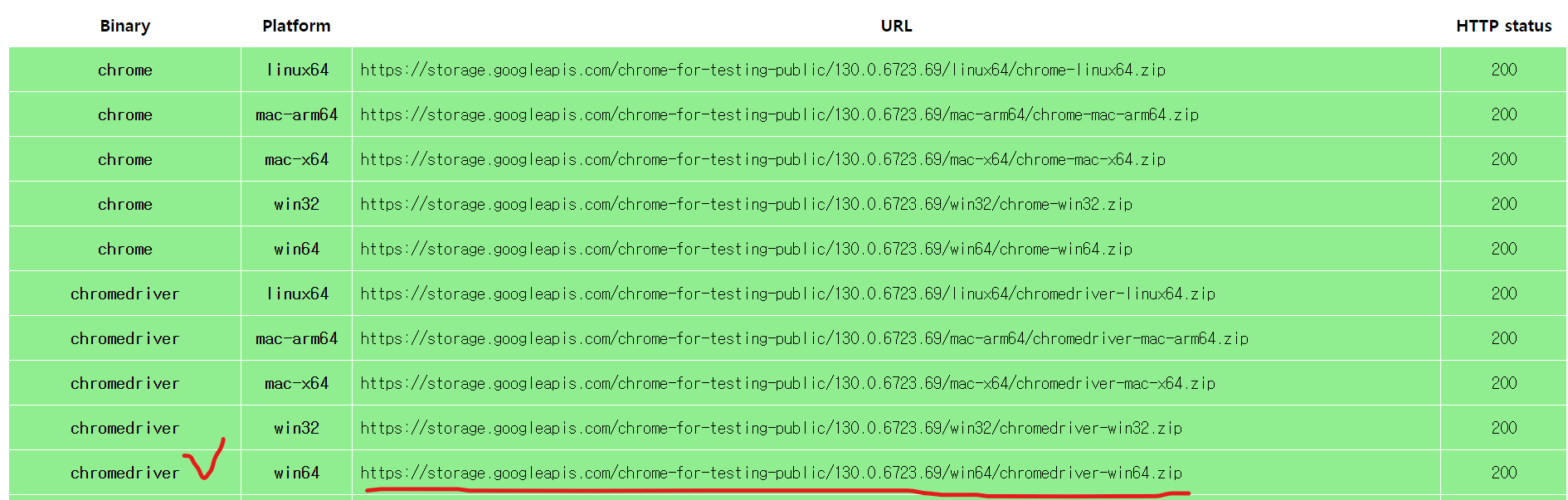
크롬웹드라이버의 위치는 내 파이썬 파일이 실행되는 장소에 넣는 것을 추천한다.
2) selenium 다운로드하기
pip install selenium
위 처럼 vscode 터미널에 입력해주면 자동으로 다운로드가 된다.
3) 희망하는 class 추출
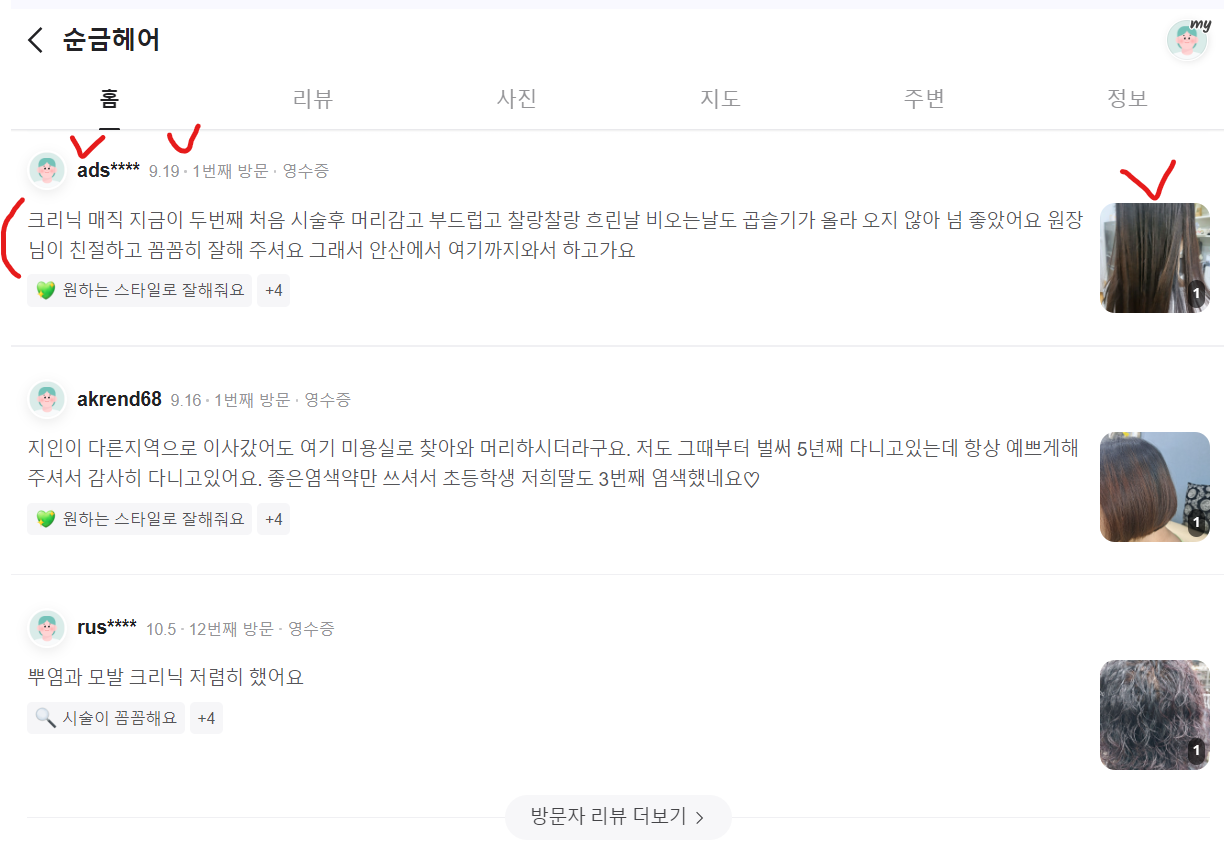
현재 페이지만 털어와보자.
이름, 사진url, 리뷰내용, 날짜, 재방문여부, 인증여부를 추출하기 위해서는
F12로 개발자 모드를 열고, 아래에서 체크된 그림을 누르면 자신이 원하는 요소의 class 이름을 알 수 있다.
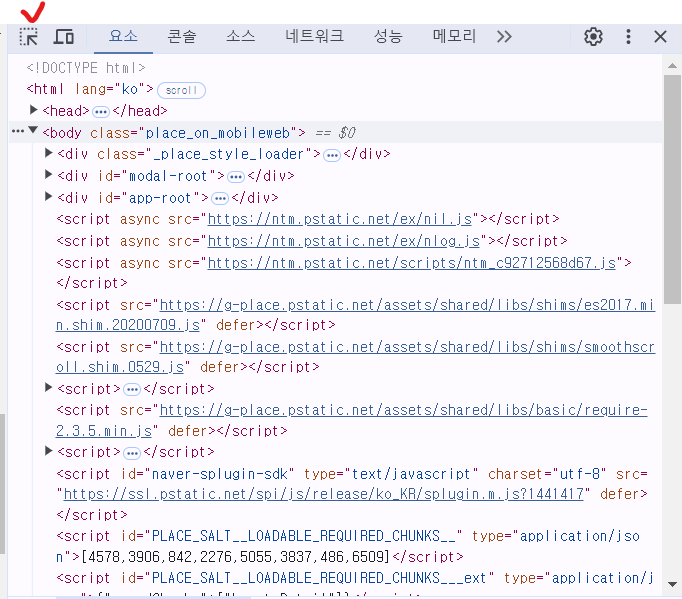
사진 같은 경우는 place_thumb img 로 가져와야 한다. ::after로 긁어오면 크롤링이 안 된다.
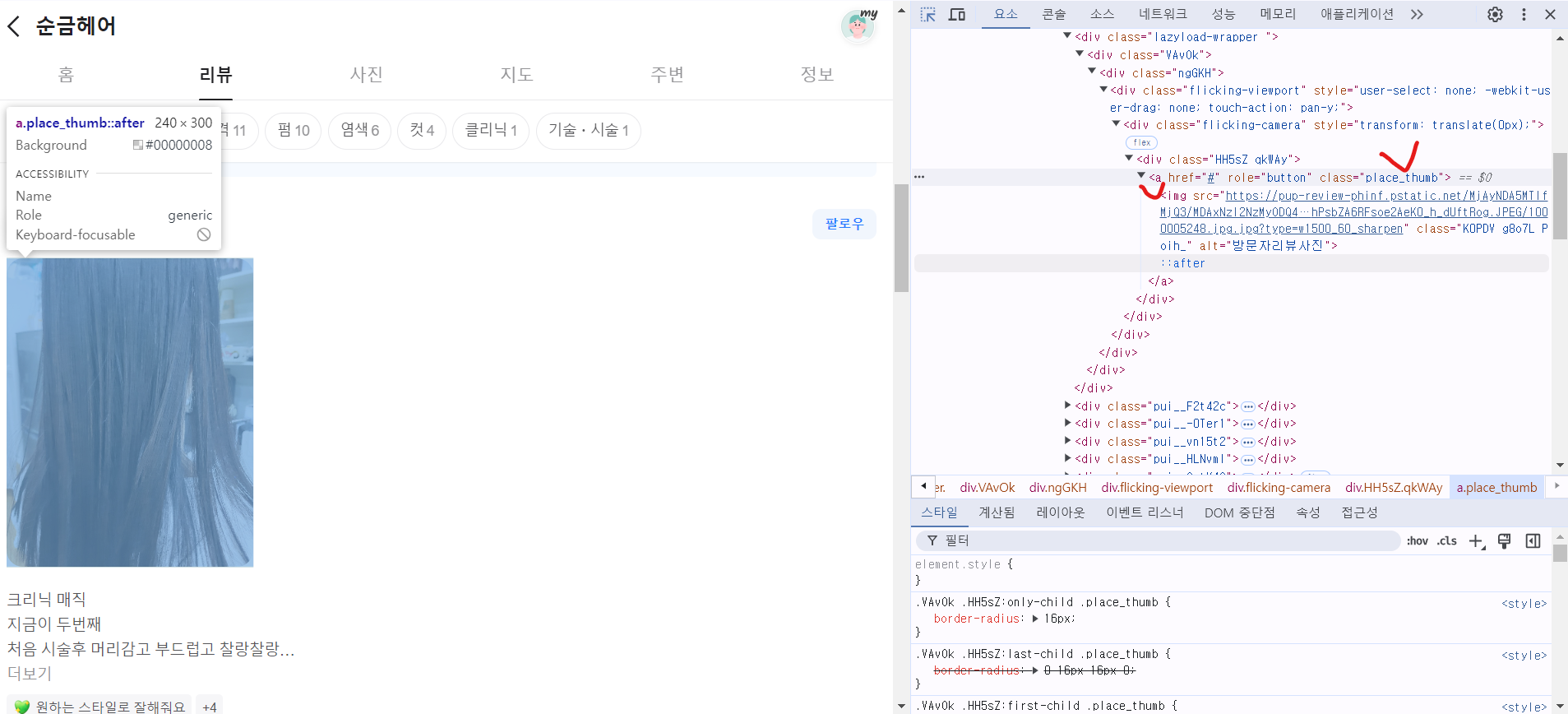
날짜, 재방문여부, 영수증도 안 나와서 초기화면에서 위치를 찾아 긁어오고 그 정보를 3부분이니까 쪼개기로 했다.
최종 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
def get_reviews():
# Chrome 옵션 설정
chrome_options = Options()
# chrome_options.add_argument("--headless") # 헤드리스 모드
# Chrome 드라이버 설정
service = Service('C:\\Users\\kdr\\Desktop\\kdrComDoc\\kdr_vscode\\Sources\\WEB\\chromedriver-win64\\chromedriver.exe') # 크롬 드라이버 경로
driver = webdriver.Chrome(service=service, options=chrome_options)
try:
# URL 접속
url = 'https://m.place.naver.com/hairshop/1216414317/home?entry=pll'
driver.get(url)
# 페이지 로딩 대기
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'pui__NMi-Dp')))
# HTML 가져오기
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 리뷰 정보 수집
reviews = soup.select('.pui__NMi-Dp') # 이름
images = soup.select('.place_thumb img') # 이미지
contents = soup.select('.pui__xtsQN-') # 리뷰 내용
date_elements = soup.select('.pui__RuLAax') # 날짜 및 재방문 여부
# 정보 출력
for i in range(len(reviews)):
name = reviews[i].text.strip() if i < len(reviews) else '정보 없음'
image = images[i]['src'] if i < len(images) and 'src' in images[i].attrs else '정보 없음'
# 공백 처리: 리뷰 내용에서 공백 2칸 이상을 1칸으로 변경
content = contents[i].text.strip().replace(' ', ' ') if i < len(contents) else '정보 없음'
while ' ' in content: # 반복적으로 공백을 줄입니다.
content = content.replace(' ', ' ')
# 날짜, 재방문 여부 및 인증 수단 추출
if i < len(date_elements):
date_info = date_elements[i].find_all('span', class_='pui__WN-kAf')
date = date_info[0].text.strip() if len(date_info) > 0 else '정보 없음'
revisit = date_info[1].text.strip() if len(date_info) > 1 else '정보 없음'
receipt = date_info[2].text.strip() if len(date_info) > 2 else '정보 없음'
else:
date = '정보 없음'
revisit = '정보 없음'
receipt = '정보 없음'
# 출력 형식
print(f"이름: {name}")
print(f"이미지: {image}")
print(f"리뷰 내용: {content}")
print(f"날짜: {date}")
print(f"재방문 여부: {revisit}")
print(f"인증 수단: {receipt}")
print("-" * 40) # 구분선
except Exception as e:
print(f"오류 발생: {e}")
finally:
# 드라이버 종료
driver.quit()
if __name__ == "__main__":
get_reviews()결과 내용
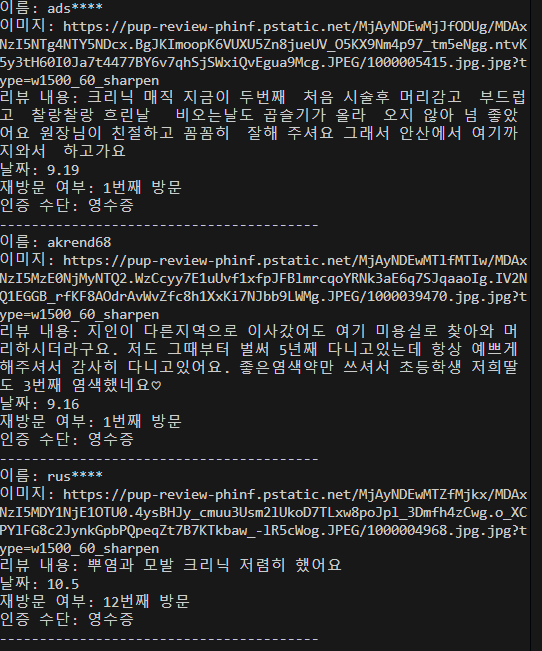
'Python' 카테고리의 다른 글
| [Python] URL로 가사 긁어와서 ppt에 자동으로 가사 붙여넣기 (1) | 2024.12.11 |
|---|---|
| 프로그래머스: 자릿수 더하기 (0) | 2024.10.15 |
| 프로그래머스: 짝수와 홀수 (1) | 2024.10.14 |
| 프로그래머스: x만큼 간격이 있는 n개의 숫자 (0) | 2024.10.14 |
| 프로그래머스: 평균 구하기 (0) | 2024.10.14 |